
We’re excited to announce the release of Ratings 2.0 for all MeetingScience Members! In this blog post, we’ll share a little bit more about the history of MeetingScience ratings and why we made the investment to build the next generation of rating capabilities.
Ratings 1.0
We introduced ratings 1.0 with the beta release of MeetingScience on 3/27/2020. MeetingScience Members and attendees of MeetingScience Member meetings could rate a meeting in the following ways (either via email or in our application):

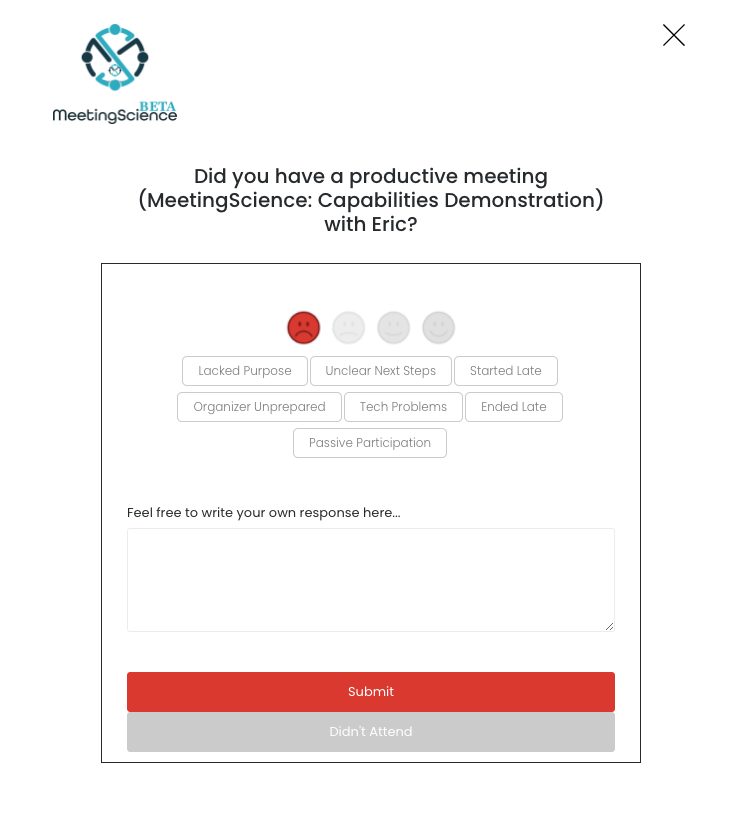
We developed these 6 positive and 7 negative attributes in partnership with Dr. Joseph Allen, the world’s leading expert on the science of meetings and a member of our scientific advisory board. You’ll note that most attributes consist of a diad – if a meeting was good (one of the top two smileys), you might indicate that the meeting had a ‘Clear Purpose,’ while if the meeting was bad (frowny smileys), you’d have the option to select ‘Lacked Purpose.’
These attributes are like an introductory course in college – they provide a great baseline and benchmark to understand individual and company meeting performance. Meeting organizers can understand how they rated themselves in relation to their meeting attendees, while companies could understand what meeting attributes drove positive vs. negative meeting performance across the company.
One of the core shortcomings of this rating methodology: you had to provide a score on a meeting before you could reference the attributes. A meeting might be great but end late, or it could be terrible but have the right attendees. And the diversity of meetings across all MeetingScience members meant that there was a knowledge gap between what we knew from initial feedback and what we could really know.
Ratings 2.0
This week, we’re introducing Ratings 2.0 to all MeetingScience members. Ratings 2.0 incorporates everything we learned about meetings, ratings, frequency, and distribution, and includes the following enhancements:
- Daily Digest (Email) – Rather than a deluge of rating requests for high-meeting-frequency participants, you’ll receive one email per day at the end of your day (between 5 – 7pm) with a daily digest of all of your meetings.
- Worst, Best, or Most Meaningful? – For an entire week, we’re going to ask you to select your worst meeting of the day. Then the next week, we’ll ask you to select your best meeting from the day. In the third week, we’ll ask you to select the most meaningful meeting of the day. And in the fourth week, we’ll ask you to rate any meeting. This cycle will continue on a rolling 4-week basis. We’re politely forcing you to make a conscious choice about the selection of a given meeting from your day in order to calibrate future recommendations and coaching tips. Over time we found a certain meeting selection bias – the tendency to rate only good meetings – which, while moderately helpful, ultimately does not provide the optimal value for meeting organizers and companies to create better meeting habits and practices.
- Attributes 2.0 – Incorporated into all meeting feedback requests, you’ll be asked to provide details on up to 6 out of a total of 57 possible meeting attributes (57 = the Rosetta Stone of meeting performance).
- How are you feeling? – We’ve also added a question about how you felt today. The goal of this feeling question is to calibrate how meeting load and strain affects (or not) your daily overall performance.
In the application, you’ll still have the ability to rate meetings on demand.
All of the enhancements introduced in Ratings 2.0 are in service to deliver personalized feedback to help organizers and others optimize the meeting experience.
Have a suggestion for how to making Ratings 2.0 ratings 3.0? Send us an email to meetingfitness@meetingscience.io.







